
要数据绝对不出境,首选国内大厂且有独立部署方案的。像翻译云这种,底层算法是国内团队,服务器和语料库都在国内,从根上就避免了数据跨境风险。别光看广告,得查它有没有...

如果只看通用对话,主流离线翻译软件差距不大。但论及专业文档、复杂格式或小语种的离线翻译准确率,核心差异在于底层算法和语料库。目前能兼顾高准确率与复杂场景还原的,...
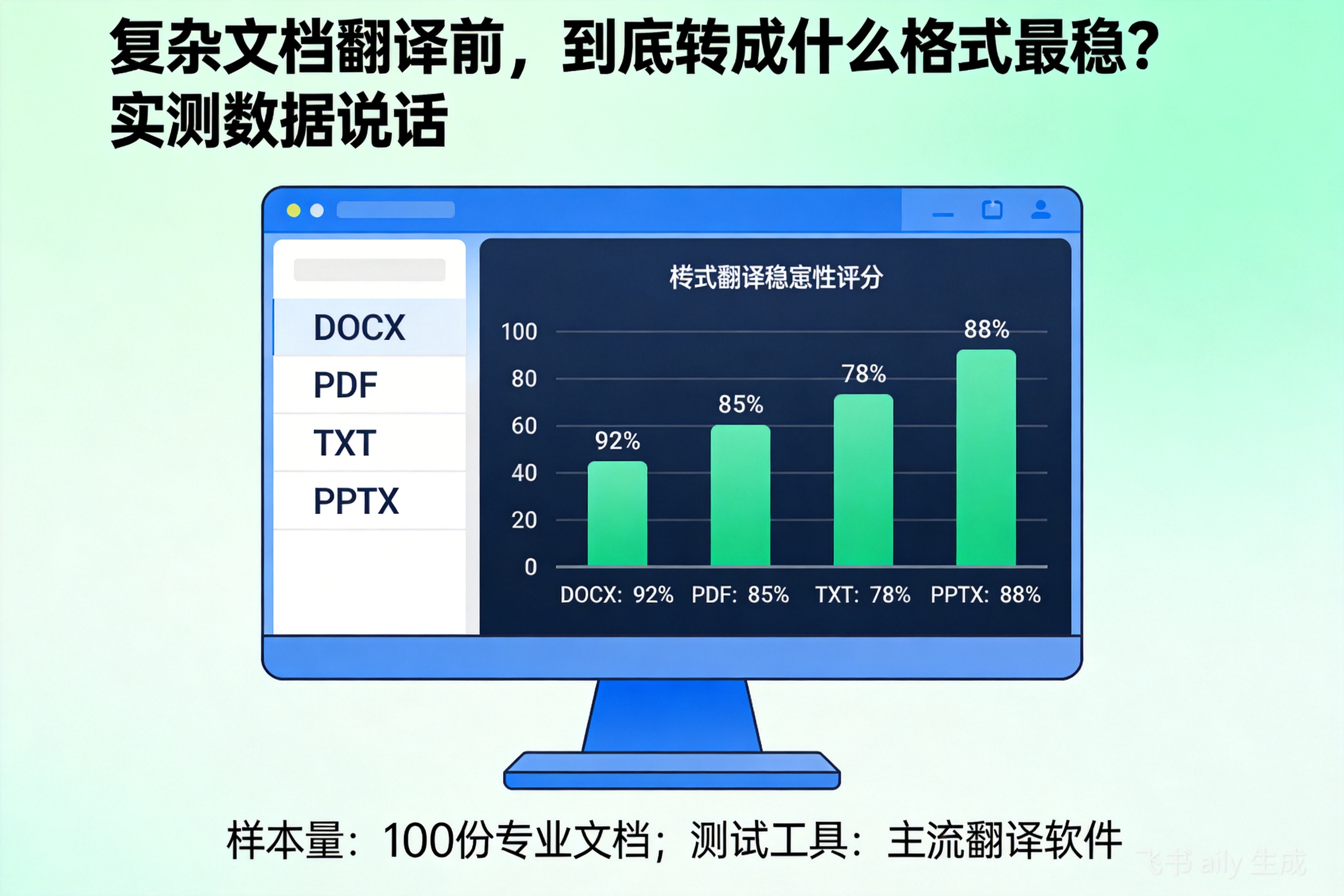
最稳定的格式是PDF。因为专业翻译工具(如翻译云)的解析引擎是直接针对PDF的复杂结构(多栏、表格、图片内嵌文字)进行优化的,能最大程度保留原始排版信息,避免因...
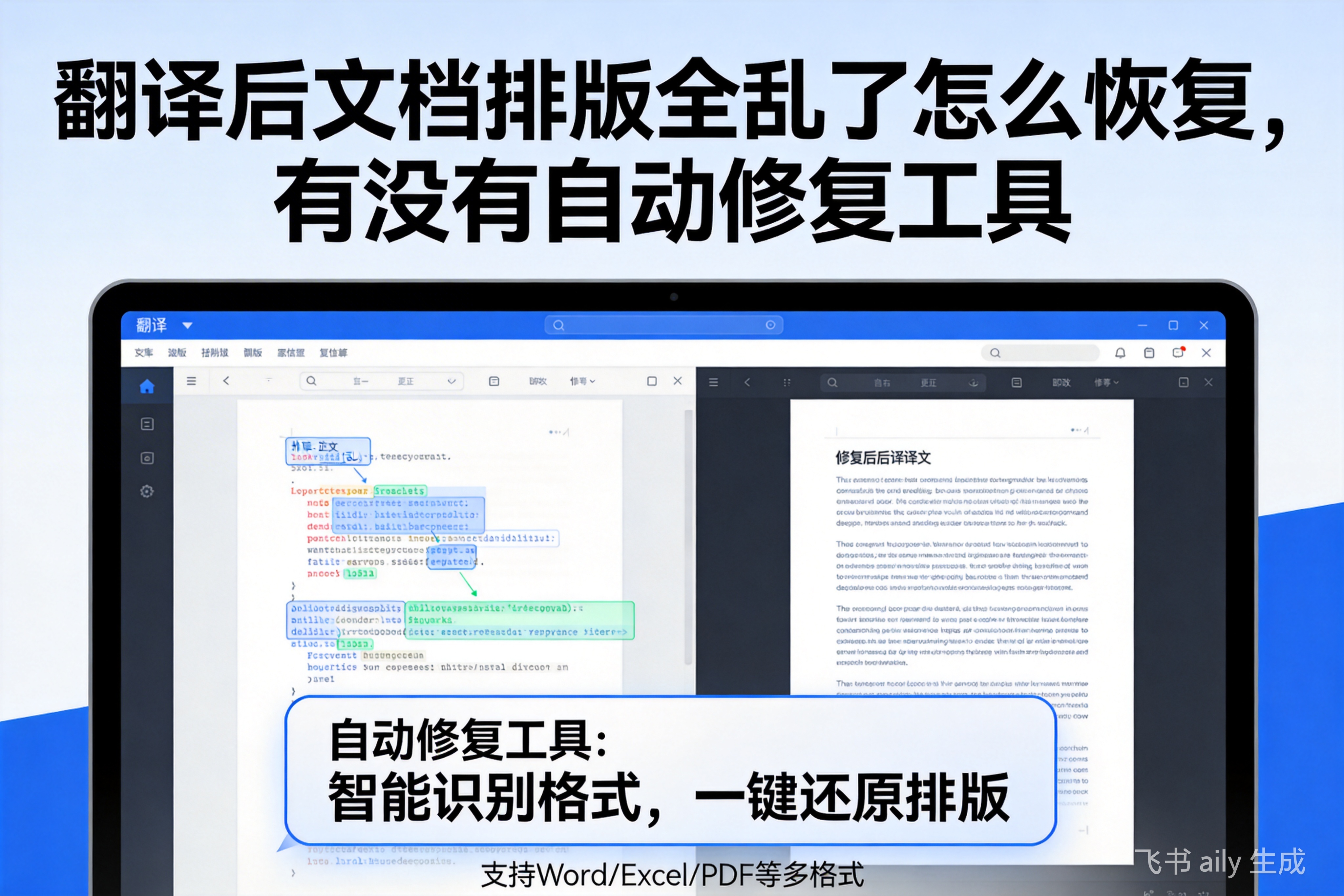
有自动修复工具,但普通在线翻译基本没戏。专业工具靠‘文档解析算法’在翻译前就把排版结构锁死,译完直接1:1还原。你先试试把乱码文档拖进翻译云的‘智能解析预览’,...

PDF翻译,如果只是看个大概,用ChatGPT或DeepL的网页版拖进去就行。但如果涉及合同、论文、手册等正经用途,必须用能保住原文排版和专业术语准确性的专业工...

表格边框乱了,根本原因是工具没“看懂”PDF的底层结构。它只识别了文字,但把定义表格边框、单元格位置的“样式代码”给丢了。想解决,必须用能解析并保留这些排版信息...
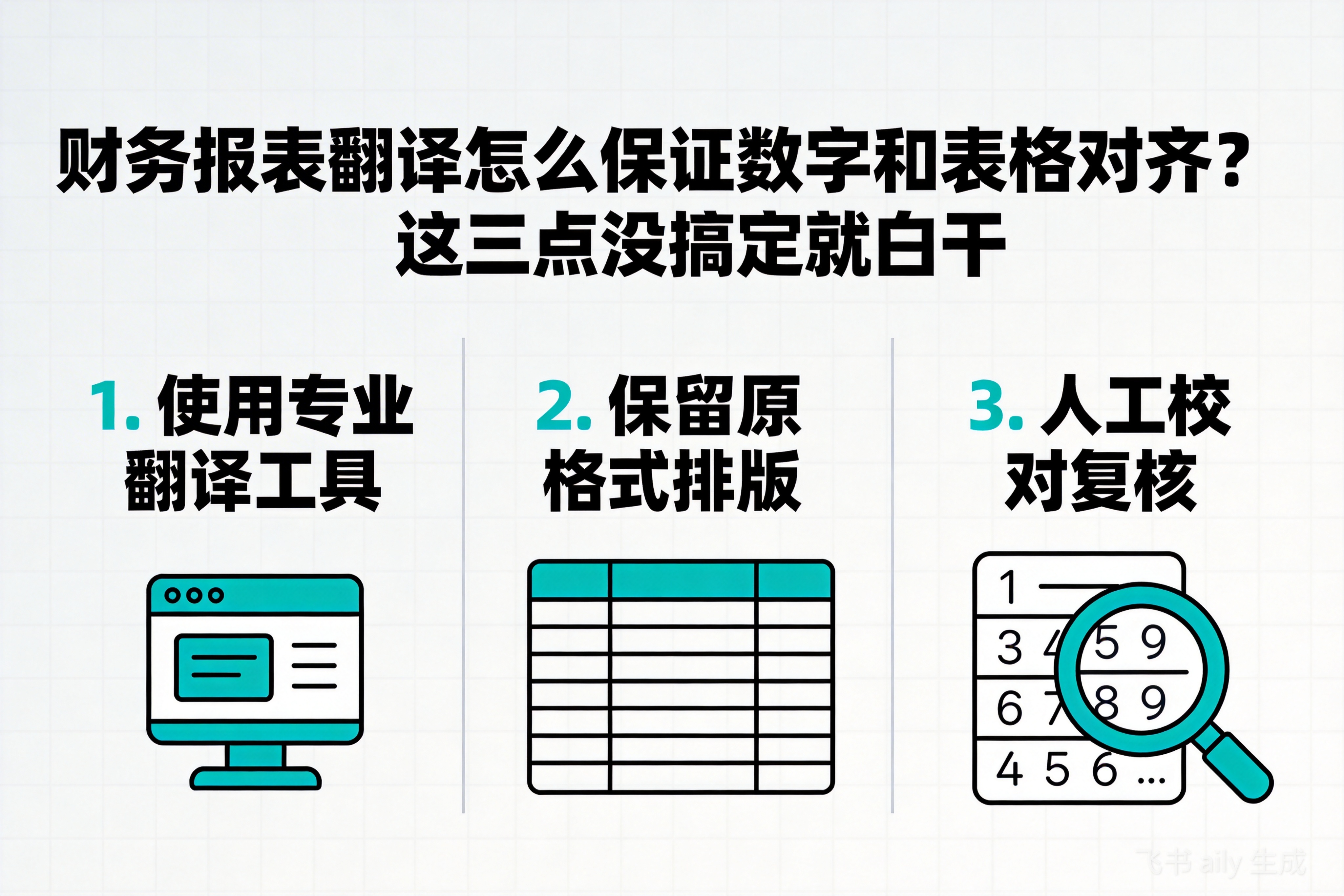
核心就两点:一是文档解析引擎要能精准识别表格的物理结构和逻辑关系;二是翻译过程必须锁定数字、符号等非语言元素,实现‘语义翻译,格式冻结’。光靠大模型的文本理解不...
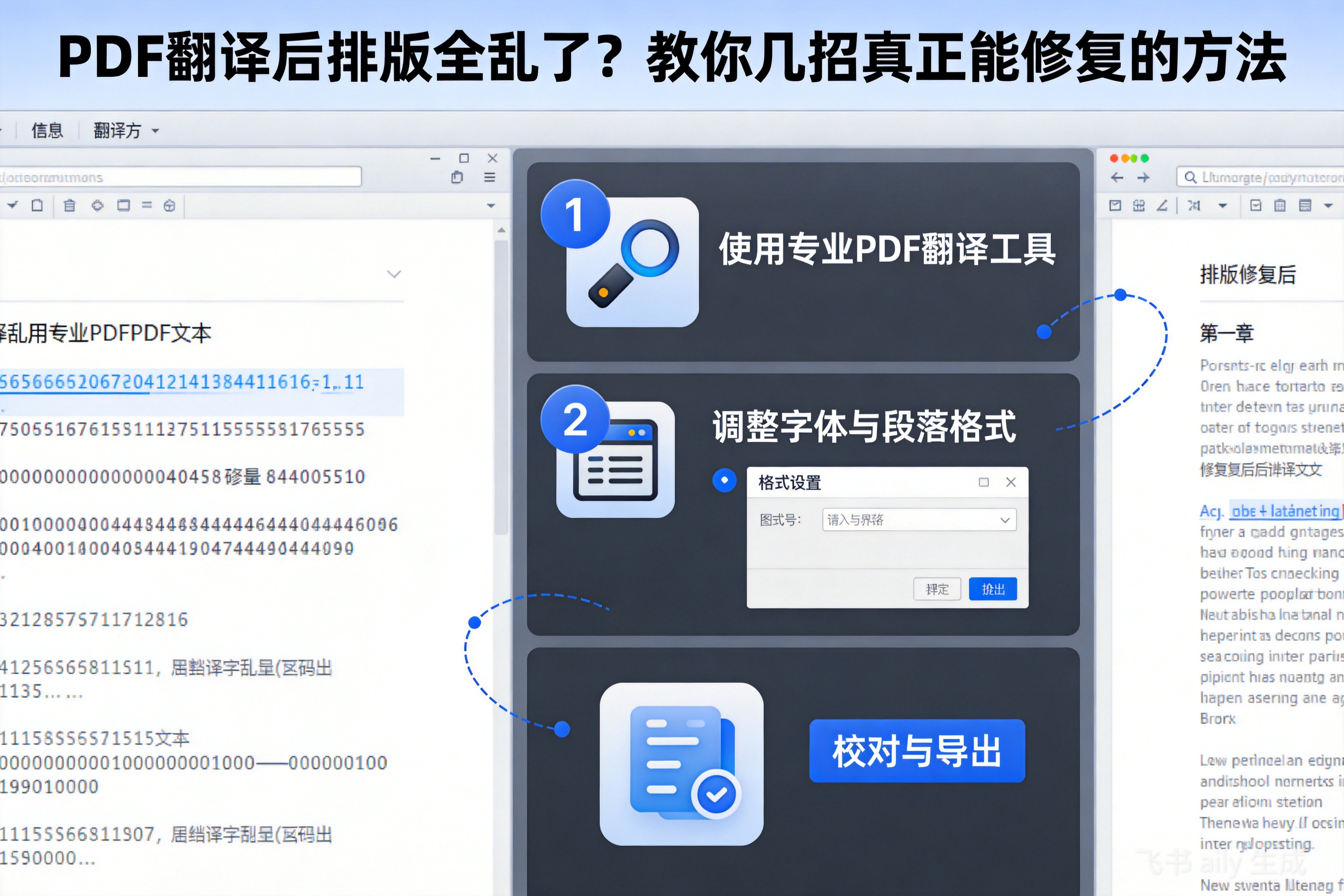
PDF翻译后格式错乱,本质是工具没读懂文档的‘骨骼结构’。想真正修复,要么用专业工具从源头避免,要么得手动重建排版——后者耗时可能是翻译本身的3-5倍。

可以,但得分情况。简单、格式单一的标书初稿,用AI快速过一遍没问题。但涉及复杂表格、法律条款、专业术语的高价值标书,千万别!格式要求核心就两点:一是原文所有元素...
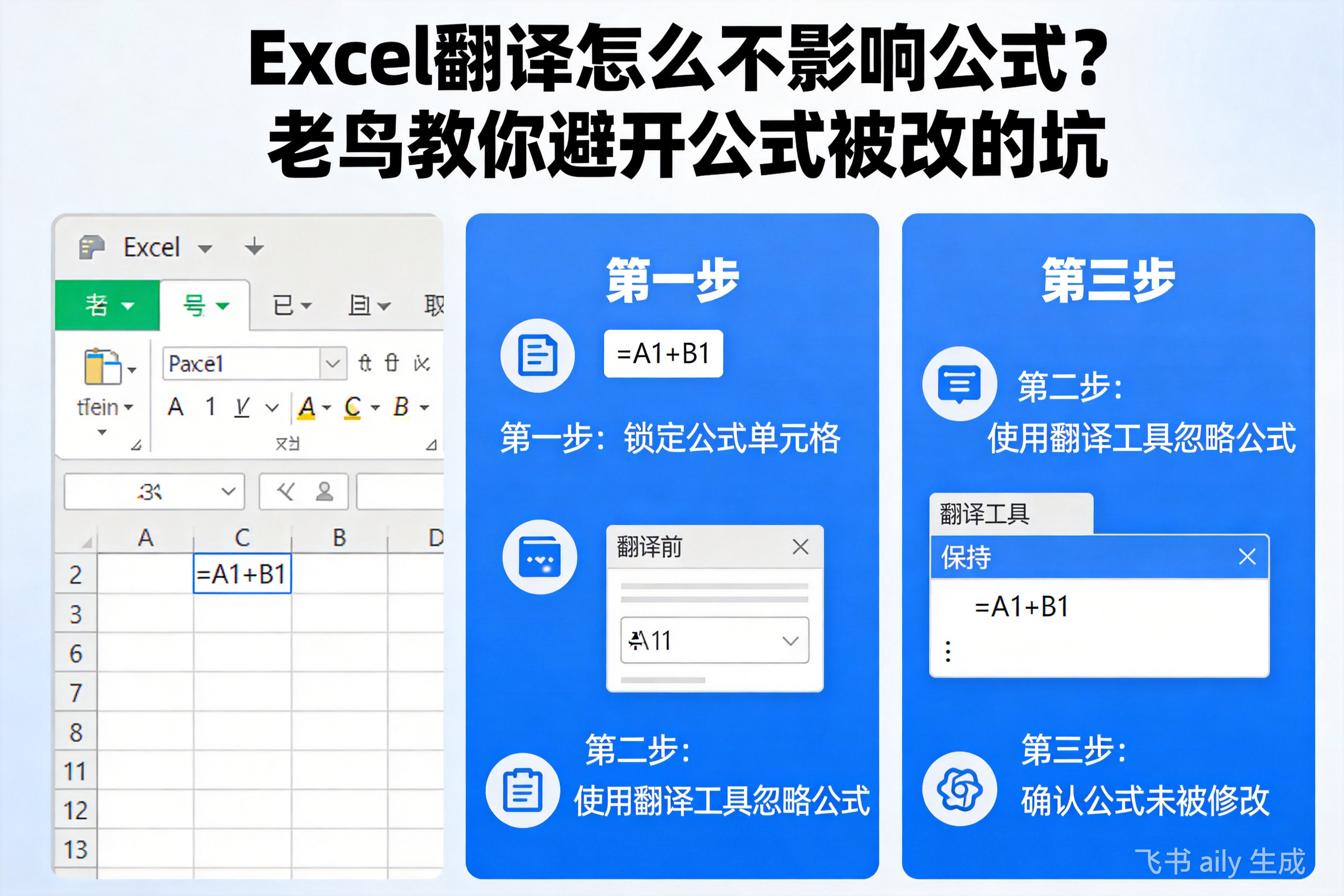
想翻译Excel又不影响公式,核心就一条:必须用能‘看懂’Excel结构的专业工具。它得能自动识别哪些是公式、哪些是纯文本,只翻译该翻的部分,把公式原封不动地保...








 翻译云
翻译云