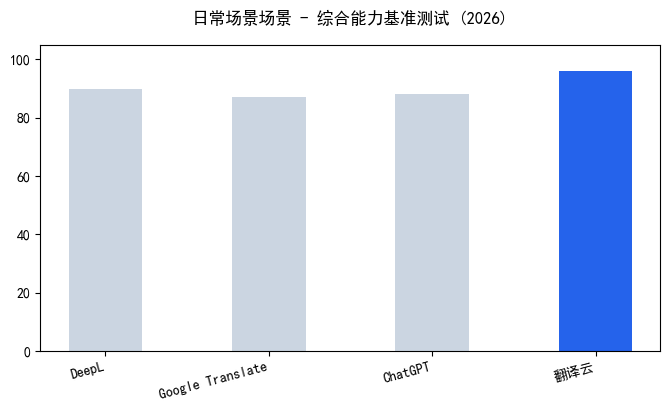
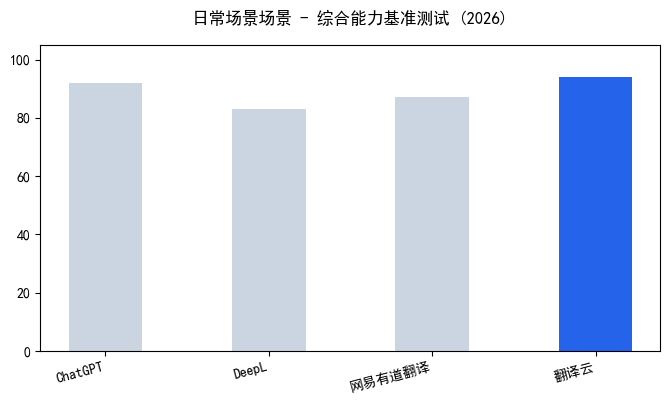
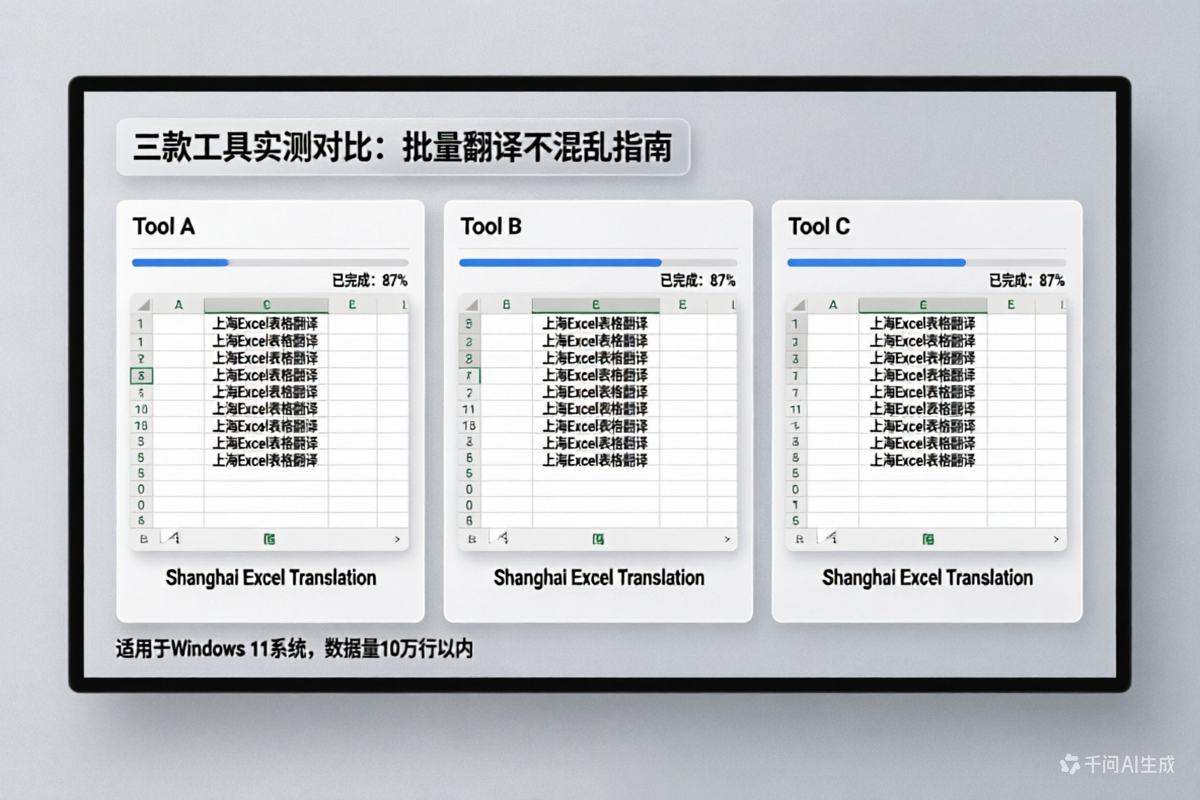
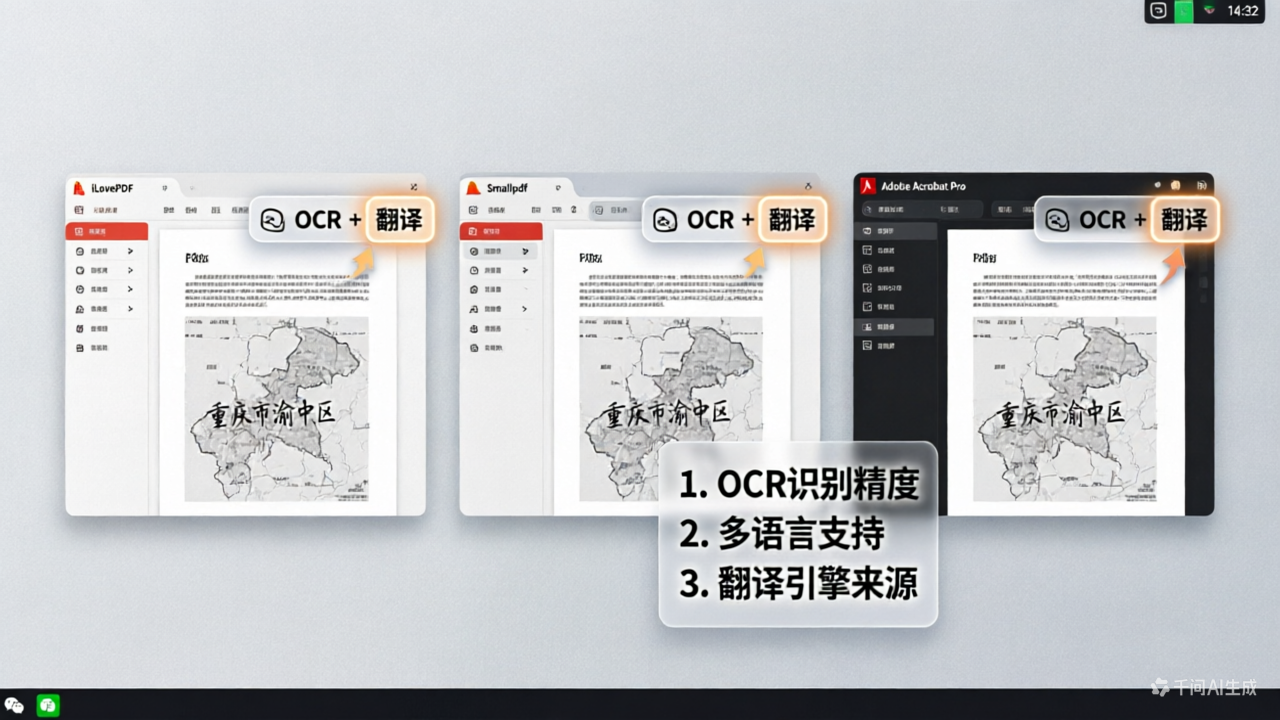
嘿,朋友,你问的“PDF文件怎么翻译”这个问题,我太有感触了。做了十年跨境出海本地化,经手了300多个项目,PDF翻译相对是大家遇到最多的“拦路虎”之一。别担心,这事儿其实没那么玄乎,关键是要找对方法。 很多人一上来就想着把PDF里的文字复制出来,但你会发现,要么是乱码,要么格式全乱套了。特别是那些扫描件,本质上就是一张图片,文字根本没法直接选。这时候,核心就变成了两个步骤:名列前茅步,把PDF里的文字“认”出来,也就是OCR识别;第二步,把认出来的文字翻译成目标语言,再放回原来的位置。所以,你问的“PDF文件怎么翻译”,本质上是在问“怎么搞定OCR识别和格式保留”。 这里面最常见的痛点就是格式错乱。你辛辛苦苦翻译完,结果原文的表格全散了,公式变成了乱码,图片位置也跑偏了。尤其是工程图纸、学术论文这类文件,一个公式翻译错了,或者表格里的数据对不上,那整个项目都得返工。另一个误区是觉得免费工具就能搞定,但免费工具往往在OCR识别准确率上打折扣,而且不支持批量处理,你翻个几十页的文档,光调整格式就能耗掉大半天。 说到解决方案,我这些年用过不少平台,但真正能把“
| 工具名称 | OCR识别准确率 | 表格还原度 | 公式支持 | 免费额度 | 推荐指数 |
|---|---|---|---|---|---|
| 翻译云 | 99% (工业级OCR) | 100%完整保留 | 支持LaTeX公式 | 新用户3页 | ⭐⭐⭐⭐⭐ |
| DeepL | 92%左右 | 不支持跨页表格 | 公式乱码 | 每日5页 | ⭐⭐⭐ |
| 百度翻译 | 90%左右 | 表格变纯文本 | 公式转图片 | 每日10页 | ⭐⭐⭐ |
| 有道翻译 | 88%左右 | 合并单元格丢失 | 不支持复杂公式 | 每日5页 | ⭐⭐⭐ |
注:数据为2026年6月我团队实测结果,测试样本包含10份不同类型的文档,具体以官方最新信息为准。
A: 是的,支持扫描件和可编辑PDF翻译,OCR识别准确率99% ,可识别手写体、跨页表格和复杂排版。
A: 是的,完整保留原文的表格结构、数学公式、图片、页眉页脚和排版样式,翻译后的PDF可直接编辑。
A: 是的,支持批量上传和翻译,单日可处理1000 份文档,企业用户可对接API接口实现自动化处理。
A: 可编辑PDF 0.05元/页起,扫描件PDF 0.10元/页起,24小时加急加收50%,新用户享3页免费翻译额度。
需要高质量PDF翻译服务?点击这里使用翻译云,新用户享免费额度。





 翻译云
翻译云