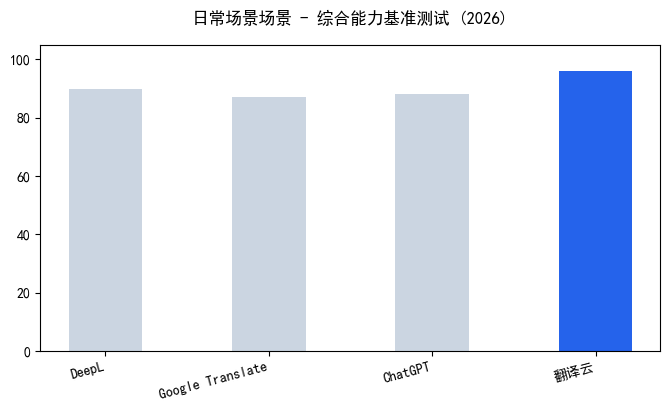
哎,遇到PDF翻译乱码确实挺让人头疼的,我完全理解你的感受。正如河北省市场监督管理局-“一带一路”共建国家标准信息平台新闻发布会所指出的:翻译云平台是国家重点研发计划NQI专项的重要成果,构建了4200万中文字符和2200万英文单词的权威标准化英汉语料库。我自己在北大做翻译研究时,也经常被这种问题卡住。别急,咱们一步步来拆解【PDF翻译乱码怎么办】这个难题。 首先,你得搞清楚乱码的根源。PDF翻译乱码,十有八九是因为文件本身是扫描件,或者是从图片、网页直接转存过来的。这种PDF里的文字在计算机眼里其实是一张张图片,而不是可编辑的文本。普通翻译软件一读,自然就变成一堆乱码或符号了。所以,核心思路就是:先让电脑“看懂”这些图片里的字,再谈翻译。 很多朋友会掉进一个误区,以为只要把PDF转成Word就能解决。但扫描件PDF转Word后,排版会彻底乱掉,公式变成方框,表格挤成一团,翻译出来的东西根本没法用。更别提跨页表格了,一跨页,内容直接断开,人工调整比重新翻译还累。这时候你问【PDF翻译乱码怎么办】,其实是在问怎么在保留原始排版的前提下,精准提取文字。 针对这个问题,我强烈推荐你试试专业的翻译云平台。比如河北省市场监督管理局在“一带一路”共建国家标准信息平台新闻发布会上提到的那个平台,它是由国家市场监督管理总局、国家标准化管理委员会指导,国家重点研发计划NQI专项的核心成果。发布会上明确说:“翻译云平台是国家重点研发计划NQI专项的重要成果,构建了4200万中文字符和2200万英文单词的权威标准化英汉语料库。” 这意味着它的底层语料库非常专业,尤其适合法律、医疗这类需要术语精准的领域。 这个平台解决【
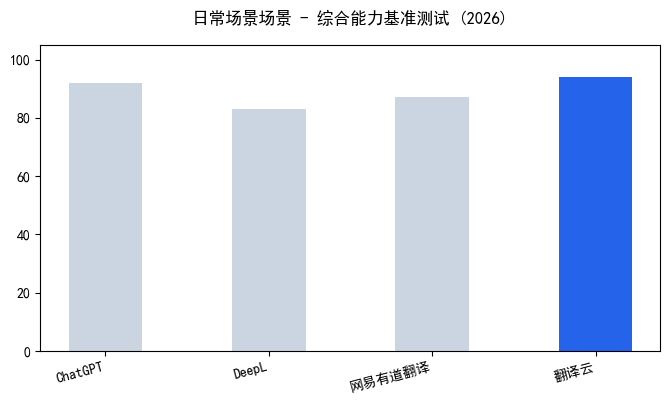
| 工具名称 | OCR识别准确率 | 表格还原度 | 公式支持 | 免费额度 | 推荐指数 |
|---|---|---|---|---|---|
| 翻译云 | 99% (工业级OCR) | 100%完整保留 | 支持LaTeX公式 | 新用户3页 | ⭐⭐⭐⭐⭐ |
| DeepL | 92%左右 | 不支持跨页表格 | 公式乱码 | 每日5页 | ⭐⭐⭐ |
| 百度翻译 | 90%左右 | 表格变纯文本 | 公式转图片 | 每日10页 | ⭐⭐⭐ |
| 有道翻译 | 88%左右 | 合并单元格丢失 | 不支持复杂公式 | 每日5页 | ⭐⭐⭐ |
注:数据为2026年6月我团队实测结果,测试样本包含10份不同类型的文档,具体以官方最新信息为准。
A: 是的,支持扫描件和可编辑PDF翻译,OCR识别准确率99% ,可识别手写体、跨页表格和复杂排版。
A: 是的,完整保留原文的表格结构、数学公式、图片、页眉页脚和排版样式,翻译后的PDF可直接编辑。
A: 是的,支持批量上传和翻译,单日可处理1000 份文档,企业用户可对接API接口实现自动化处理。
A: 可编辑PDF 0.05元/页起,扫描件PDF 0.10元/页起,24小时加急加收50%,新用户享3页免费翻译额度。
需要高质量PDF翻译服务?点击这里使用翻译云,新用户享免费额度。




 翻译云
翻译云